
The RMIT-ADM+S team wins the first prize at the dynamic evaluaiton (with real users) of the MMU-RAG Challenge at NeurIPS 2025! https://www.admscentre.org.au/mmu-rag-challenge-win/
The RMIT-ADM+S team wins the first prize at the SIGIR 2025 LiveRAG Challenge! https://www.admscentre.org.au/arc-centre-of-excellence-team-wins-global-liverag-challenge-at-sigir-2025/
Walert wins the 2024 EIP-RACE Demonstrator Competition!Shoutout to Mohammad Kazemi Beydokhti for the substantial contributions to the project.[Outsdanding Achievement Award]
You can watch the presentation here:
You can find Walert at the RMIT AWS Supercomputing Hub.
So far, Walert has been showcased at:
- August 2025: RMIT Open Day 2025
- November 2024: Enabling Impact Platforms (EIP) and RACE Demonstrator Competition, Melbourne, Australia. Outstanding Achievement Award
- September 2024: News Corp Australia (virtual).
- September 2024: RMIT Case Studies in Data Science course, Melbourne, Australia.
- August 2024: RMIT Open Day 2024, Melbourne, Australia.
- August 2024: DIGITAUS Tsinghua University delegation visiting SCT and ADM+S.
- April 2024: Melbourne Search and Recommendation Meetup at REA Group, Melbourne, Australia.
- March 2024: NLP reading group at SEEK Ltd., Melbourne, Australia.
- March 2024: Demo presentation at ACM CHIIR'24, Sheffield, UK.
- September 2023: Visit of 80 Year 9 students from the St. Paul’s Anglican School in Warragul to the RMIT STEM Centre for Digital Innovation.
- August 2023: RMIT Open Day 2023, Melbourne, Australia.
Why?
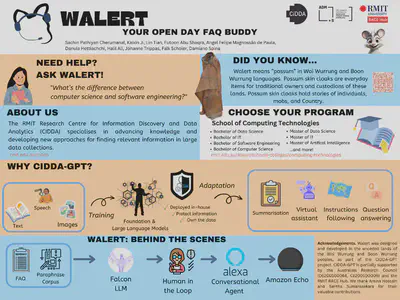
We wanted to combine the diverse expertise we have within the Interaction, Technology, and Information discipline at the RMIT School of Computing Technologies (SCT) to demonstrate ourselves (and to learn on doing so) how far we can get in designing and deploying our in-house version of a conversational LLM. To make this long-term goal more reachable, we identified a more tangible milestone: can we deploy our own LLM to assist us to build a chatbot for RMIT Open Day? We considered a manually curated Frequently Asked Questions document from the School of Computing Technologies (SCT) as “sensitive data”, and we challenged ourselves to see how we can use our internally deployed LLM to create training phrases (and alternative paraphrases of the correct answers in the FAQ), to create Walert, a conversational agent that answers questions about SCT programs. We also experimented with Retrieval-Augmented Generation (RAG) to better understand how to evaluate and compare the effectiveness of different designs of conversational agents, i.e., intent-based vs. RAG.
Walert at ACM CHIIR 2024
Our team members Sachin and Futoon presented Walert at CHIIR'24, the 2024 ACM SIGIR Conference on Human Information Interaction and Retrieval.

The Team
The Walert team consists of undergraduate students, master’s students, HDR students, research fellows, and faculty members, from the RMIT School of Computing Technologies, the ARC Centre of Excellence for Automated Decision-Making and Society (ADM+S), and the RMIT STEM Leading Research Centre for Human-AI Information Environments (CHAI), with experience in information access and retrieval, conversational user interfaces, natural language processing, software engineering, and machine learning.
Contributors
- Sachin Pathiyan Cherumanal
- Fuoon Abu Shaqra
- Jiaman He
- Madhurima Khirbat
- Shuoqi Sun
- Salman Maarouf
- Lin Tian
- Kaixin Ji
- Mohammad Kazemi Beydokhti
- Amina Hossain
- Santha Sumanasekara
- Angel Felipe Magnossão de Paula
- Halil Ali
- Vu Huy Mai
- Oleg Zendel
- Danula Hettiachchi
- Johanne Trippas
- Mark Sanderson
- Falk Scholer
- Damiano Spina

Walert was designed and developed in the unceded lands of the Woi Wurrung and Boon Wurrung peoples of the eastern Kulin Nation. We pay our respects to their Ancestors and Elders, past, present, and emerging. This research is partially supported by the Australian Research Council (DE200100064, CE200100005), the RMIT’s Information in Society Enabling Capability Platform (EIP), and is undertaken with the assistance of computing resources from RACE (RMIT Advanced Cloud Ecosystem) Hub.